
Cómo Evaluar AI Agents: Comparación de 3 Frameworks
Al evaluar AI agents, la elección del framework determina tus puntajes. Ejecuta pruebas idénticas en Strands, PydanticAI y DeepEval y los números divergen hasta 40%. Esto no es un bug. Es por diseño.
La mayoría de las comparaciones de frameworks prueban diferentes agents con diferentes rúbricas y lo llaman justo. Esta ejecuta los mismos casos de prueba, mismo modelo de evaluación (Claude Sonnet 4 en Amazon Bedrock), mismos criterios de evaluación en los tres frameworks. La única variable es la API del framework.
La divergencia revela arquitectura. Strands y PydanticAI envían rúbricas directamente al modelo de evaluación para puntuación transparente. DeepEval usa G-Eval, una técnica respaldada por investigación que descompone la evaluación en pasos chain-of-thought y pondera puntajes con probabilidades de tokens. Diferentes metodologías, diferentes resultados, ambos válidos.
Lo que aprenderás:
- Por qué los puntajes de GEval difieren del prompting directo de rúbricas (es por diseño, no un bug)
- Qué framework funciona mejor para tu stack (AWS vs type-safety vs framework-agnostic)
- Cuándo usar verificaciones determinísticas vs evaluación basada en LLM
- Por qué PydanticAI no puede evaluar listas de herramientas pre-computadas (requisito de OpenTelemetry)
Lo que realmente se está comparando:
- Strands Agents = Framework de agents + biblioteca de evaluación (
strands-agents-evals), soporta 12+ proveedores de modelos - PydanticAI = Framework de agents + biblioteca de evaluación (
pydantic-evals), soporta múltiples proveedores via Logfire - DeepEval = Framework solo de evaluación (funciona con cualquier agent)
DeepEval no construye agents. Solo los evalúa. Esto lo hace comparable a strands-agents-evals y pydantic-evals (las bibliotecas de evaluación), no a los frameworks completos Strands/PydanticAI.
El panorama de evaluación para AI agents vio más de 45 nuevos papers de investigación en los últimos 6 meses en arXiv (repositorio de preprints de acceso abierto de Cornell University), proponiendo nuevas métricas para calidad de trajectory (TRACE), detección de hallucinations (LSC), y compromisos costo-rendimiento (KAMI). Pero cuando se trata de implementar estas evaluaciones, ¿qué framework deberías usar?
¿Por qué estos 3 frameworks (y no CrewAI, LangGraph o AutoGen)?
Comparé 8 frameworks de agents por sus capacidades de evaluación. Los frameworks más populares (CrewAI, LangGraph, AutoGen, OpenAI Agents SDK, Google ADK) se enfocan en construir agents, no en evaluarlos. No incluyen bibliotecas dedicadas de evaluación.
Estos 3 fueron seleccionados porque son los únicos con SDKs de evaluación dedicados y de código abierto:
| Framework | Biblioteca de Evaluación | Qué Proporciona |
|---|---|---|
| Strands Agents | strands-agents-evals | OutputEvaluator, TrajectoryEvaluator, ToolCalled, ActorSimulator, Experiment runner |
| PydanticAI | pydantic-evals | LLMJudge, Datasets tipados con YAML, diffing de reportes, HasMatchingSpan |
| DeepEval | deepeval (standalone) | 30+ métricas: GEval, HallucinationMetric, FaithfulnessMetric, ToolCorrectnessMetric |
¿Qué pasa con los demás?
| Framework | Por Qué No Está Incluido |
|---|---|
| CrewAI | crewai test solo soporta OpenAI, proporciona puntuación básica de 1-10. Sin rúbricas, sin evaluación de trajectory, sin detección de hallucinations. |
| LangGraph | La evaluación vive en LangSmith (SaaS de pago), no en el framework de código abierto. |
| AutoGen | Tiene AutoGen Bench para benchmarking pero no un SDK de evaluación con métricas comparables. |
| OpenAI Agents SDK | Proporciona hooks de tracing pero no una biblioteca de evaluación. Combínalo con DeepEval para evaluar. |
| Google ADK | Tiene CLI adk eval pero está fuertemente acoplado al ecosistema Gemini. |
Si usas CrewAI, LangGraph o AutoGen para construir tu agent, aún necesitas uno de estos 3 frameworks para evaluarlo. DeepEval en particular es framework-agnostic y funciona con cualquier agent.
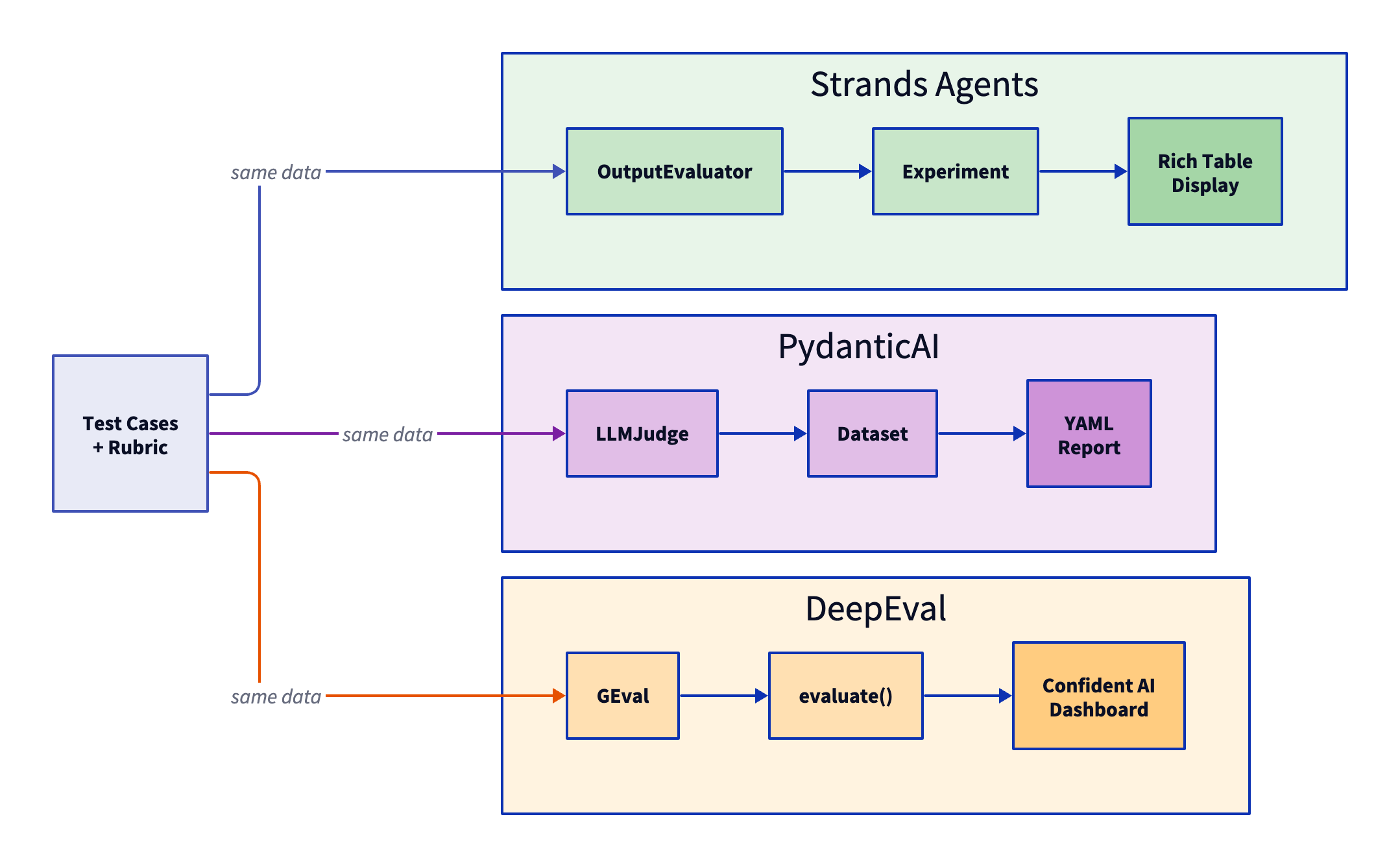
¿Qué tareas de evaluación estamos ejecutando?
Evaluamos el mismo escenario de agente asistente de viajes en los tres frameworks. El agent responde preguntas de viajeros usando herramientas (buscar vuelos, verificar disponibilidad de hoteles, obtener clima).
- Calidad de Salida - ¿La respuesta del agent es útil y precisa? (LLM-as-Judge)
- Corrección de Herramientas - ¿El agent llamó las herramientas correctas con los parámetros correctos?
- Detección de Hallucinations - ¿El agent fabricó información que no está en el contexto?
- Faithfulness - ¿La respuesta está fundamentada en la información recuperada?
Mismos casos de prueba. Mismo modelo de evaluación (Claude en Amazon Bedrock). Mismas rúbricas donde sea posible.
Ronda 1: Calidad de Salida (LLM-as-Judge)
Respuesta rápida: Los tres frameworks soportan LLM-as-Judge con rúbricas personalizadas, pero Strands requiere menos líneas (7), PydanticAI ofrece las opciones de configuración más completas (modos de puntuación + aserción), y DeepEval soporta la gama más amplia de criterios personalizados via GEval. Strands y PydanticAI soportan Bedrock nativamente; DeepEval requiere un wrapper personalizado.
LLM-as-Judge es la técnica de evaluación más fundamental: usar un modelo de lenguaje grande para puntuar si la salida del agent cumple criterios de calidad. Los tres frameworks soportan este patrón, pero la API difiere significativamente.
Strands Agents (7 líneas)
Strands usa OutputEvaluator con una rúbrica personalizada, haciéndolo la opción más concisa para LLM-as-Judge básico:
from strands_evals import Experiment, Case
from strands_evals.evaluators import OutputEvaluator
cases = [
Case(input="Find flights from NYC to London for next Friday",
expected_output="Should include airline, price range, and departure times"),
]
evaluator = OutputEvaluator(
rubric="Rate the response on helpfulness (0-1). A helpful response includes "
"specific flight options with airlines, prices, and times. Penalize "
"vague or generic responses.",
model="us.anthropic.claude-sonnet-4-20250514-v1:0",
)
experiment = Experiment(cases=cases, evaluators=[evaluator])
reports = experiment.run_evaluations(lambda case: agent(case.input))
reports[0].display()PydanticAI (10 líneas)
PydanticAI envuelve casos en un Dataset y proporciona modos de puntuación y aserción separados, dándote más control sobre criterios de aprobación/fallo:
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import LLMJudge
dataset = Dataset(
cases=[
Case(
name="flight_search",
inputs="Find flights from NYC to London for next Friday",
expected_output="Should include airline, price range, and departure times",
),
],
evaluators=[
LLMJudge(
rubric="Rate the response on helpfulness. A helpful response includes "
"specific flight options with airlines, prices, and times. "
"Penalize vague or generic responses.",
model="anthropic:claude-sonnet-4-6",
include_input=True,
include_expected_output=True,
score={"include_reason": True},
),
],
)
report = dataset.evaluate_sync(lambda inputs: agent(inputs))
report.print(include_input=True)DeepEval (12 líneas)
DeepEval usa GEval con parámetros de evaluación explícitos, permitiéndote controlar qué campos ve el evaluador:
from deepeval import evaluate
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
test_case = LLMTestCase(
input="Find flights from NYC to London for next Friday",
actual_output=agent("Find flights from NYC to London for next Friday"),
expected_output="Should include airline, price range, and departure times",
)
metric = GEval(
name="Helpfulness",
criteria="Rate the response on helpfulness. A helpful response includes "
"specific flight options with airlines, prices, and times. "
"Penalize vague or generic responses.",
evaluation_params=[
LLMTestCaseParams.INPUT,
LLMTestCaseParams.ACTUAL_OUTPUT,
LLMTestCaseParams.EXPECTED_OUTPUT,
],
threshold=0.5,
)
result = evaluate(test_cases=[test_case], metrics=[metric])Veredicto: ¿Qué Framework Gana?
| Aspecto | Strands | PydanticAI | DeepEval |
|---|---|---|---|
| Líneas de código | 7 | 10 | 12 |
| Bedrock nativo | Sí | Sí | Necesita wrapper personalizado |
| Formato de puntuación | 0.0-1.0 | 0.0-1.0 + pass/fail | 0.0-1.0 |
| Razón incluida | Sí | Sí (configurable) | Sí |
| Evaluación por lotes | Experiment.run_evaluations() | Dataset.evaluate_sync() | evaluate() |
| Método de prompting | Rúbrica directa → LLM | Rúbrica directa → LLM | G-Eval (CoT + logprobs) |
Strands es el más conciso. PydanticAI ofrece la mayor configuración (modos separados de puntuación vs aserción). DeepEval usa GEval, una técnica respaldada por investigación del paper “G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment”.
⚠️ Por qué los puntajes pueden diferir: Incluso con el mismo modelo y texto de rúbrica, GEval usa una estrategia de prompting fundamentalmente diferente:
- Descomposición chain-of-thought - Desglosa la evaluación en pasos explícitos
- Ponderación de logprobs - Usa probabilidades de tokens para ponderar puntajes
- Template estructurado - Formato de prompt optimizado para alineación humana
Esto es por diseño. GEval optimiza para correlación con juicios humanos, no para puntuación idéntica al prompting directo de rúbricas. Strands y PydanticAI optimizan para transparencia y personalizabilidad.
Ronda 2: Evaluación de Corrección de Herramientas
Respuesta rápida: Strands proporciona extracción de trajectory integrada y verificaciones determinísticas de herramientas (costo cero). DeepEval tiene un ToolCorrectnessMetric dedicado con comparación basada en LLM. El HasMatchingSpan de PydanticAI requiere instrumentación OpenTelemetry y no es comparable a los otros dos para validación simple de lista de herramientas.
La corrección de herramientas mide si el agent llamó las herramientas correctas con los parámetros correctos. Esto es crítico para agents que interactúan con APIs y bases de datos, porque una llamada incorrecta a una herramienta puede causar efectos secundarios en el mundo real.
⚠️ PydanticAI excluido de comparación directa: El evaluador HasMatchingSpan de PydanticAI requiere traces completos de OpenTelemetry de ejecución de agent en vivo. No puede evaluar listas de herramientas pre-computadas como ["search_flights", "check_availability"], haciéndolo fundamentalmente incomparable a ToolCalled de Strands y ToolCorrectnessMetric de DeepEval para validación básica de herramientas.
Strands Agents (con extracción de trajectory)
Strands automáticamente extrae el uso de herramientas de traces de ejecución del agent, haciendo la evaluación de trajectory fluida:
from strands_evals import Experiment, Case
from strands_evals.evaluators import TrajectoryEvaluator
from strands_evals.extractors import tools_use_extractor
traj_eval = TrajectoryEvaluator(
rubric="The agent should search for flights first, then check availability. "
"Calling weather tools is optional but acceptable.",
model="us.anthropic.claude-sonnet-4-20250514-v1:0",
)
cases = [
Case(
input="Find flights from NYC to London for next Friday",
expected_trajectory=["search_flights", "check_availability"],
),
]
def task_with_trajectory(case):
agent.messages = []
response = agent(case.input)
traj_eval.update_trajectory_description(
tools_use_extractor.extract_tools_description(agent)
)
trajectory = tools_use_extractor.extract_agent_tools_used_from_messages(
agent.messages
)
return {"output": str(response), "trajectory": trajectory}
experiment = Experiment(cases=cases, evaluators=[traj_eval])
reports = experiment.run_evaluations(task_with_trajectory)Bonus: Verificación determinística de herramientas (sin LLM necesario, costo cero)
Para verificaciones simples de “¿se llamó esta herramienta?”, Strands proporciona verificación instantánea sin llamadas API:
from strands_evals.evaluators import ToolCalled
# Check if a specific tool was called (instant, no API call)
experiment = Experiment(
cases=cases,
evaluators=[ToolCalled(tool_name="search_flights")],
)PydanticAI (con detección de herramientas basada en spans)
PydanticAI usa spans de OpenTelemetry para detectar uso de herramientas, requiriendo código de evaluador personalizado para validación de trajectory:
from dataclasses import dataclass
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import Evaluator, EvaluatorContext, HasMatchingSpan
dataset = Dataset(
cases=[
Case(
name="flight_search",
inputs="Find flights from NYC to London for next Friday",
metadata={"expected_tools": ["search_flights", "check_availability"]},
),
],
evaluators=[
HasMatchingSpan(
query={"name_contains": "search_flights"},
evaluation_name="called_search_flights",
),
],
)
# Custom evaluator for full trajectory check
@dataclass
class ToolSequenceCheck(Evaluator):
def evaluate(self, ctx: EvaluatorContext) -> dict[str, bool]:
tool_spans = ctx.span_tree.find(lambda n: "tool" in n.name.lower())
tool_names = [s.name for s in tool_spans]
expected = ctx.metadata.get("expected_tools", [])
return {
"all_tools_called": all(t in tool_names for t in expected),
"correct_order": self._check_order(tool_names, expected),
}
def _check_order(self, actual, expected):
positions = []
for tool in expected:
if tool in actual:
positions.append(actual.index(tool))
return positions == sorted(positions)DeepEval (con objetos ToolCall)
DeepEval usa objetos estructurados ToolCall con validación explícita de parámetros y verificaciones de orden:
from deepeval import evaluate
from deepeval.metrics import ToolCorrectnessMetric
from deepeval.test_case import LLMTestCase, ToolCall
test_case = LLMTestCase(
input="Find flights from NYC to London for next Friday",
actual_output="I found 3 flights...",
tools_called=[
ToolCall(name="search_flights", input_parameters={"origin": "NYC", "dest": "LHR"}),
ToolCall(name="check_availability", input_parameters={"flight_id": "BA117"}),
],
expected_tools=[
ToolCall(name="search_flights", input_parameters={"origin": "NYC", "dest": "LHR"}),
ToolCall(name="check_availability"),
],
)
metric = ToolCorrectnessMetric(
threshold=0.5,
should_consider_ordering=True,
should_exact_match=False,
)
result = evaluate(test_cases=[test_case], metrics=[metric])Veredicto: ¿Qué Framework Gana?
| Aspecto | Strands | PydanticAI | DeepEval |
|---|---|---|---|
| Extracción de trajectory | Extractor integrado | Via spans OpenTelemetry | Objetos ToolCall manuales |
| Eval de trajectory basada en LLM | TrajectoryEvaluator | No comparable (solo OTEL) | ToolCorrectnessMetric |
| Verificación determinística | ToolCalled (costo cero) | HasMatchingSpan (solo OTEL) | N/A |
| Validación de orden | in_order_match_scorer | Código personalizado | should_consider_ordering |
| Validación de parámetros | Via rúbrica | Via atributos de span | should_exact_match |
| Funciona con listas de herramientas pre-computadas | Sí | No (requiere traces en vivo) | Sí |
Strands gana por simplicidad con extracción de trajectory integrada de mensajes del agent. DeepEval tiene la API de ToolCall más estructurada con comparación dedicada basada en LLM. PydanticAI es el más flexible via árboles de spans pero requiere instrumentación OpenTelemetry, haciéndolo adecuado solo para evaluación de agent en vivo, no análisis pre-computado.
Ronda 3: Detección de Hallucinations
Respuesta rápida: DeepEval proporciona un HallucinationMetric construido específicamente que descompone afirmaciones y verifica cada una contra el contexto. Strands y PydanticAI usan LLM-as-judge de propósito general con rúbricas personalizadas, lo cual es flexible pero menos especializado. DeepEval gana para detección de hallucinations con su métrica dedicada y conteo de contradicciones por contexto.
La detección de hallucinations mide si el agent fabrica información no presente en el contexto fuente. Esta es una de las dimensiones de evaluación más críticas, con investigación reciente (LSC, enero 2026) mostrando que métodos de detección zero-shot pueden identificar contenido fabricado sin datos de entrenamiento.
Strands Agents
Strands usa OutputEvaluator con una rúbrica enfocada en hallucinations:
from strands_evals import Experiment, Case
from strands_evals.evaluators import OutputEvaluator
cases = [
Case(
input="What is the baggage policy for Delta flights to London?",
expected_output="Based on the context: 2 checked bags, 23kg each, free for international",
),
]
hallucination_eval = OutputEvaluator(
rubric="Score 1.0 if the response ONLY contains information present in the "
"expected output (ground truth). Score 0.0 if the response includes "
"any fabricated details such as specific prices, dates, or policies "
"not mentioned in the ground truth. Partially correct responses "
"should score between 0.3-0.7.",
model="us.anthropic.claude-sonnet-4-20250514-v1:0",
)
experiment = Experiment(cases=cases, evaluators=[hallucination_eval])
reports = experiment.run_evaluations(lambda case: agent(case.input))PydanticAI
PydanticAI usa LLMJudge con modos de puntuación y aserción separados para detección de hallucinations:
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import LLMJudge
dataset = Dataset(
cases=[
Case(
name="baggage_policy",
inputs="What is the baggage policy for Delta flights to London?",
expected_output="Based on the context: 2 checked bags, 23kg each, free for international",
),
],
evaluators=[
LLMJudge(
rubric="Does the response ONLY contain information present in the "
"expected output? Score 0.0 for fabricated details, 1.0 for "
"fully grounded responses.",
model="anthropic:claude-sonnet-4-6",
include_expected_output=True,
score={"include_reason": True, "evaluation_name": "hallucination"},
assertion={"include_reason": True, "evaluation_name": "grounded"},
),
],
)
report = dataset.evaluate_sync(lambda inputs: agent(inputs))DeepEval (HallucinationMetric dedicado)
DeepEval proporciona un HallucinationMetric especializado que descompone respuestas en afirmaciones y verifica cada una contra el contexto fuente:
from deepeval import evaluate
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What is the baggage policy for Delta flights to London?",
actual_output=agent("What is the baggage policy for Delta flights to London?"),
context=[
"Delta international flights include 2 checked bags at 23kg each, free of charge.",
"Carry-on must fit in overhead bin. One personal item allowed.",
],
)
metric = HallucinationMetric(threshold=0.5)
result = evaluate(test_cases=[test_case], metrics=[metric])Veredicto: ¿Qué Framework Gana?
| Aspecto | Strands | PydanticAI | DeepEval |
|---|---|---|---|
| Métrica dedicada | No (via rúbrica OutputEvaluator) | No (via rúbrica LLMJudge) | Sí (HallucinationMetric) |
| Contexto como input | Via expected_output | Via expected_output | Campo de contexto dedicado |
| Método de puntuación | LLM judge con rúbrica | LLM judge con rúbrica | Verificación afirmación por afirmación |
| Granularidad | Puntuación única | Puntuación + aserción | Conteo de contradicciones por contexto |
DeepEval gana aquí con un HallucinationMetric construido específicamente que descompone afirmaciones y verifica cada una contra el contexto. Strands y PydanticAI usan LLM-as-judge de propósito general con rúbricas personalizadas. Este enfoque es flexible pero menos especializado para detección de hallucinations.
Ronda 4: Evaluación por Lotes
Respuesta rápida: PydanticAI tiene el mejor reporte con diffing de baseline (comparar v1 vs v2). DeepEval tiene la mayor cantidad de métricas disponibles (30+). Strands tiene la API más limpia para mezclar evaluadores LLM y determinísticos en un solo experimento.
La evaluación del mundo real ejecuta múltiples métricas en múltiples casos de prueba al mismo tiempo. Esta sección compara cómo cada framework maneja ejecución paralela, tipos de métricas mixtas, y reporte.
Strands Agents
Strands combina múltiples evaluadores en un solo Experiment, ejecutando automáticamente todas las combinaciones:
from strands_evals import Experiment, Case
from strands_evals.evaluators import (
OutputEvaluator, TrajectoryEvaluator, ToolCalled,
)
cases = [
Case(input="Find flights NYC to London",
expected_output="Flight options with prices",
expected_trajectory=["search_flights"]),
Case(input="What's the weather in Paris tomorrow?",
expected_output="Temperature and conditions",
expected_trajectory=["get_weather"]),
Case(input="Book hotel in Tokyo for 3 nights",
expected_output="Booking confirmation with dates and price",
expected_trajectory=["search_hotels", "book_hotel"]),
]
experiment = Experiment(
cases=cases,
evaluators=[
OutputEvaluator(rubric="Is the response helpful and specific?"),
TrajectoryEvaluator(rubric="Did the agent use the right tools?"),
ToolCalled(tool_name="search_flights"),
],
)
reports = experiment.run_evaluations(task_function)
for report in reports:
report.display()PydanticAI
PydanticAI usa Dataset.evaluate_sync() con un parámetro max_concurrency para ejecución paralela:
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import LLMJudge, EqualsExpected, HasMatchingSpan
dataset = Dataset(
cases=[
Case(name="flights", inputs="Find flights NYC to London",
expected_output="Flight options with prices"),
Case(name="weather", inputs="What's the weather in Paris tomorrow?",
expected_output="Temperature and conditions"),
Case(name="hotel", inputs="Book hotel in Tokyo for 3 nights",
expected_output="Booking confirmation with dates and price"),
],
evaluators=[
LLMJudge(rubric="Is the response helpful and specific?",
score={"include_reason": True}),
],
)
report = dataset.evaluate_sync(task_function, max_concurrency=3)
report.print(include_input=True, include_averages=True)DeepEval
DeepEval usa AsyncConfig para controlar ejecución paralela y soporta el rango más amplio de métricas integradas:
from deepeval import evaluate
from deepeval.metrics import (
GEval, AnswerRelevancyMetric, HallucinationMetric, ToolCorrectnessMetric,
)
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.evaluate.configs import AsyncConfig
test_cases = [build_test_case(q) for q in questions]
metrics = [
GEval(name="Helpfulness",
criteria="Is the response helpful and specific?",
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT]),
AnswerRelevancyMetric(threshold=0.7),
HallucinationMetric(threshold=0.5),
]
result = evaluate(
test_cases=test_cases,
metrics=metrics,
async_config=AsyncConfig(max_concurrent=5),
)Veredicto: ¿Qué Framework Gana?
| Aspecto | Strands | PydanticAI | DeepEval |
|---|---|---|---|
| Ejecución paralela | run_evaluations_async() | parámetro max_concurrency | AsyncConfig(max_concurrent=N) |
| Tipos de métricas mixtas | LLM + determinístico | LLM + determinístico + span | Solo LLM (30+ métricas) |
| Formato de reporte | Tabla Rich via .display() | Tabla Rich via .print() | Consola + dashboard Confident AI |
| Diffing de reportes | No | Sí (parámetro baseline=) | Via Confident AI |
| Exportar | Archivo JSON | Archivo YAML/JSON | JSON/CSV + cloud |
PydanticAI tiene el mejor reporte con diffing de baseline (comparar v1 vs v2). DeepEval tiene las métricas más disponibles. Strands tiene la API más limpia para mezclar evaluadores LLM y determinísticos.
¿Cuál es la comparación completa de características?
Esta tabla resume cada capacidad de evaluación en los tres frameworks. Úsala como referencia al elegir un framework para tus necesidades específicas de evaluación.
| Característica | Strands + evals | PydanticAI + evals | DeepEval |
|---|---|---|---|
| LLM-as-Judge | OutputEvaluator | LLMJudge | GEval |
| Evaluación de trajectory | TrajectoryEvaluator + extractors | SpanTree + custom | ToolCorrectnessMetric |
| Detección de hallucinations | Via rúbrica | Via rúbrica | HallucinationMetric |
| Faithfulness | FaithfulnessEvaluator (trace) | Via rúbrica | FaithfulnessMetric |
| Verificaciones determinísticas | Equals, Contains, ToolCalled | Equals, Contains, IsInstance | N/A |
| Evaluación multi-agent | InteractionsEvaluator | Evaluador personalizado | N/A |
| Simulación multi-turn | ActorSimulator | N/A | ConversationalTestCase |
| Generación de casos de prueba | ExperimentGenerator | N/A | deepeval generate |
| Bedrock nativo | Sí | Sí | Wrapper personalizado |
| OpenTelemetry | Integrado | Via Logfire | N/A |
| Serialización de dataset | JSON | YAML/JSON | JSON/CSV |
| Comparación de reportes | No | Diffing de baseline | Confident AI |
| Integración con pytest | Via Experiment | dataset.evaluate_sync() | assert_test() / deepeval test |
| Total de métricas integradas | 12 evaluadores | 6 evaluadores + custom | 30+ métricas |
Pruébalo tú mismo
El notebook acompañante ejecuta todas las comparaciones con código en vivo. Puedes reproducir cada resultado de este artículo.
Un notebook Jupyter acompañante con ejemplos de código ejecutables está disponible en el repositorio de GitHub. El notebook incluye comparaciones lado a lado de los tres frameworks en las mismas tareas de evaluación.
Configuración
cd blog-framework-comparison
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txtPreguntas frecuentes
¿Qué framework de evaluación de AI agents es más fácil de aprender? Strands Agents requiere el menor número de líneas de código (7 líneas para LLM-as-Judge). PydanticAI está cerca con 10 líneas. DeepEval requiere la mayor configuración, especialmente para modelos que no son OpenAI donde necesitas una clase wrapper personalizada.
¿Strands, PydanticAI y DeepEval soportan Amazon Bedrock?
Strands y PydanticAI soportan Bedrock nativamente (configuración de una línea). DeepEval requiere un wrapper personalizado DeepEvalBaseLLM que mapea la API de Bedrock a la interfaz de DeepEval. El wrapper agrega aproximadamente 25 líneas de código.
¿Necesito OpenTelemetry para evaluar AI agents?
Solo para evaluadores basados en trace en Strands (como FaithfulnessEvaluator y ToolSelectionAccuracyEvaluator). Los evaluadores basados en output en los tres frameworks funcionan sin OpenTelemetry. PydanticAI usa OpenTelemetry via Logfire para evaluación basada en spans.
¿Cuál es el costo de ejecutar evaluaciones de AI agents?
Cada evaluador basado en LLM hace llamadas API al modelo de evaluación, lo que incurre en costos de tokens. Strands proporciona evaluadores determinísticos (como ToolCalled, Equals, Contains) que se ejecutan instantáneamente con costo cero. DeepEval y PydanticAI también tienen opciones determinísticas (Equals, Contains, IsInstance).
¿Puedo usar múltiples frameworks de evaluación juntos?
Sí. Puedes usar las métricas especializadas de DeepEval (como HallucinationMetric) junto con Strands Agents para el runtime del agent y captura de trajectory. Los frameworks evalúan outputs, no agents directamente, así que el framework de agent y el framework de evaluación son elecciones independientes.
Conclusión
No hay un framework de evaluación “mejor” único. La elección correcta depende de tu stack, prioridades y qué estás comparando.
Punto clave: Diferentes metodologías producen diferentes puntajes por diseño.
- Strands y PydanticAI envían rúbricas directamente al LLM (transparente, personalizable)
- DeepEval usa técnicas respaldadas por investigación como G-Eval (optimizado para alineación humana)
- PydanticAI requiere OpenTelemetry para evaluación de herramientas (solo traces en vivo)
- Strands y DeepEval funcionan con datos pre-computados (pruebas más simples)
Cuándo usar cada uno:
Strands Agents es la opción más cohesiva si quieres un framework unificado para creación y evaluación de agents. Creación de agents, llamado de herramientas, captura de trajectory y evaluación viven en el mismo ecosistema. El sistema de hooks y métricas integradas significa que la evaluación está instrumentada en el runtime del agent, no agregada después del hecho. Mejor para equipos que quieren un framework completo de agents con evaluación integrada. Soporta 12+ proveedores de modelos incluyendo AWS Bedrock, OpenAI, Anthropic, Gemini, Ollama, y LiteLLM (para 100+ proveedores más).
PydanticAI es la opción más elegante si valoras type safety y pipelines de evaluación estructurados. Datasets YAML, diffing de reportes, y el protocolo Evaluator lo hacen ideal para equipos que quieren evaluación-como-código con garantías fuertes. Mejor para equipos priorizando type safety y pipelines reproducibles.
DeepEval es la opción más completa si quieres métricas especializadas sin construirlas tú mismo. Más de 30 métricas, incluyendo detección de hallucinations construida específicamente y verificación de faithfulness, te permiten evaluar inmediatamente sin escribir rúbricas personalizadas. Mejor para evaluación framework-agnostic con técnicas validadas por investigación.
Los conceptos de evaluación (LLM-as-judge, puntuación de trajectory, detección de hallucinations) son independientes del framework. Los papers de investigación y técnicas detrás de ellos funcionan independientemente de qué framework elijas. Para la lista completa de 45+ papers que informaron esta comparación, consulta el archivo RESEARCH.md.
Amazon Bedrock AgentCore: Una Cuarta Opción
Amazon Bedrock AgentCore proporciona evaluadores integrados y despliegue administrado para agents. Si estás comprometido con AWS y quieres una solución completamente administrada, AgentCore vale la pena considerar junto con los frameworks de código abierto.
Evaluadores Integrados
AgentCore incluye 13 evaluadores pre-construidos accesibles via el CLI de AgentCore y AWS SDK. Estos evaluadores cubren dimensiones comunes de evaluación sin requerir código personalizado:
| Evaluador | Qué Mide | Cuándo Usar |
|---|---|---|
Builtin.Helpfulness | Calidad y relevancia de output | Mismo caso de uso que Strands OutputEvaluator |
Builtin.GoalSuccessRate | Precisión de completar tareas | Métrica binaria de éxito (comparar con puntuación de trajectory) |
Builtin.ToolSelection | Corrección de elección de herramientas | Igual que Strands ToolCalled o DeepEval ToolCorrectnessMetric |
Builtin.Faithfulness | Fundamentación en contexto recuperado | Igual que DeepEval FaithfulnessMetric |
Builtin.Harmfulness | Cumplimiento de seguridad y política | Detecta outputs inseguros |
Cómo funcionan las evaluaciones: Invocas el comando CLI agentcore run eval con tu ID de agent, el nombre del evaluador deseado (como Builtin.Helpfulness), y un archivo de casos de prueba. AgentCore ejecuta el agent en cada caso de prueba y devuelve un reporte JSON con puntajes y razonamiento para cada consulta. Consulta la Guía de Evaluación de AgentCore para ejemplos.
Captura de Trace para Observabilidad
AgentCore captura traces completos de ejecución cuando habilitas el parámetro enableTrace en la llamada API invoke_agent. Los traces incluyen:
- Rationale: El razonamiento del agent antes de cada llamada de herramienta
- Invocaciones de herramientas: Qué herramientas fueron llamadas con qué parámetros
- Observaciones: Resultados devueltos de cada herramienta
- Pasos de orquestación: La secuencia completa de toma de decisiones
Todos los traces se registran automáticamente en Amazon CloudWatch para análisis y monitoreo. Puedes consultar traces usando CloudWatch Logs Insights o exportarlos a S3 para análisis por lotes. Consulta la Documentación de Tracing de Bedrock Agent para detalles del esquema de trace.
Cuándo usar AgentCore:
- Ya estás en AWS y quieres un servicio administrado
- Necesitas observabilidad nativa de CloudWatch y logging de cumplimiento
- Tu equipo prefiere infraestructura-como-código (CDK/CloudFormation) sobre scripts de evaluación personalizados
- No necesitas evaluar agents en otros proveedores de cloud
Cuándo usar frameworks de código abierto:
- Despliegue multi-cloud (Strands funciona con Bedrock, OpenAI, Anthropic, Ollama)
- Necesitas control fino sobre lógica de evaluación
- Quieres iterar rápidamente en métricas personalizadas sin desplegar funciones Lambda
- Investigación o prototipado donde la flexibilidad importa más que infraestructura administrada
Recursos de AgentCore
- Documentación de AWS Bedrock Agents
- Evaluadores Integrados de AgentCore
- Prueba y Evaluación de Agents
Gracias!