
How to Evaluate AI Agents: 3 Framework Comparison
How to Evaluate AI Agents, compare Strands Agents, PydanticAI, and DeepEval for AI agent evaluation. Same test cases, same rubrics, different frameworks. Code examples and results.
Find all the code here Evaluate AI Agents with Strands
Your AI agent produces answers. But how do you know if they’re good?
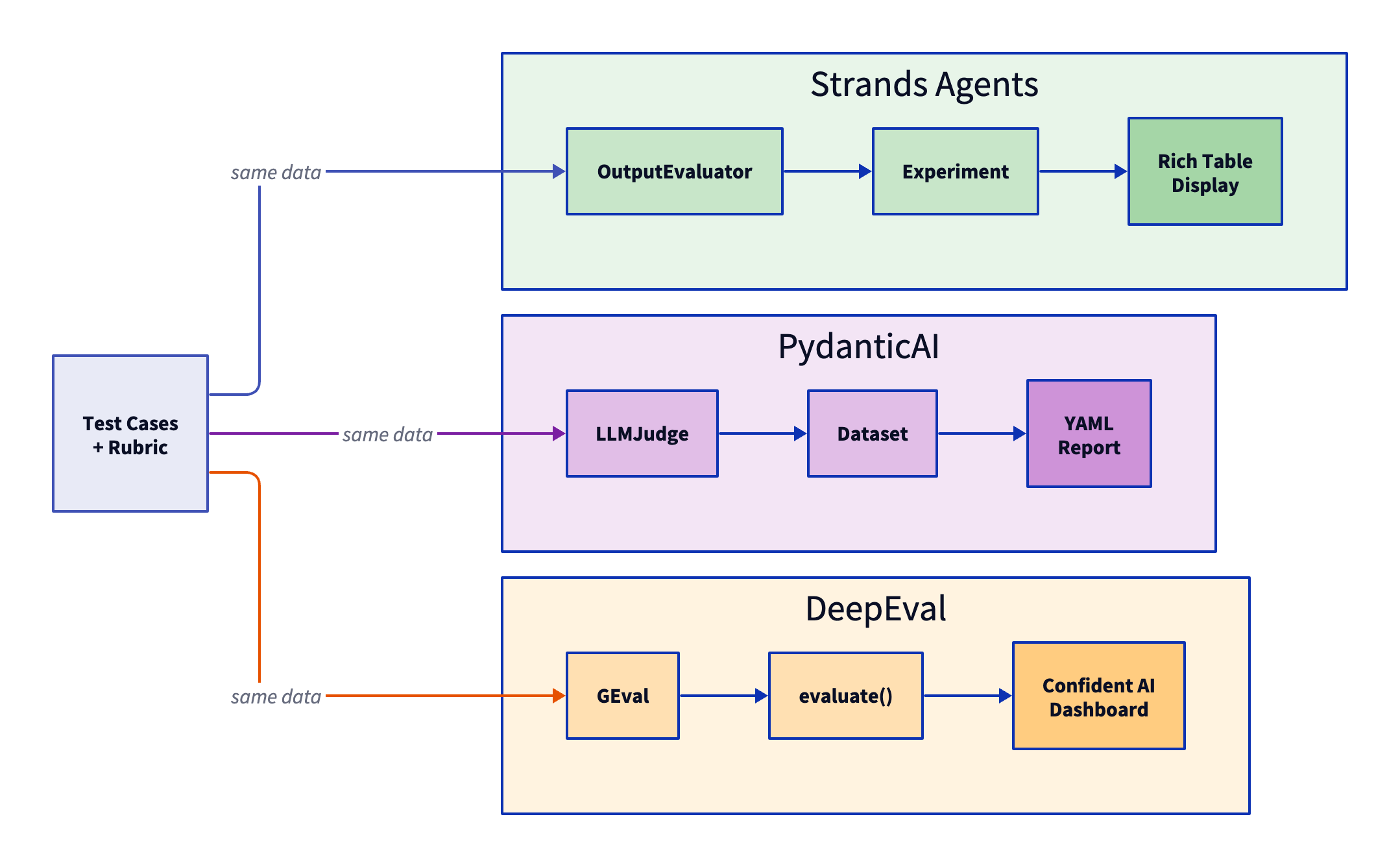
Three frameworks promise to solve this: Strands Agents, PydanticAI, and DeepEval. They all use LLM-as-Judge. They all detect hallucinations. But when you run the exact same test through each one, the scores diverge.
The problem: Framework comparisons usually test different things and call it “fair.” This post is different. We run identical test cases with the same judge model (gpt-4o-mini) through all three frameworks. The only variable? The framework API.
What you’ll learn:
- Why GEval scores differ from direct rubric prompting (it’s by design, not a bug)
- Which framework works best for your stack (AWS vs type-safety vs framework-agnostic)
- When to use deterministic checks vs LLM-based evaluation
- Why PydanticAI can’t evaluate pre-computed tool lists (OpenTelemetry requirement)
What’s actually being compared:
- Strands Agents = Agent framework + evaluation library (
strands-agents-evals) - PydanticAI = Agent framework + evaluation library (
pydantic-evals) - DeepEval = Evaluation-only framework (works with any agent)
DeepEval doesn’t build agents—it only evaluates them. This makes it comparable to strands-agents-evals and pydantic-evals (the evaluation libraries), not to the full Strands/PydanticAI frameworks.
The evaluation landscape for AI agents saw 45+ new research papers in the past 6 months on arXiv (Cornell University’s open-access preprint repository), proposing new metrics for trajectory quality (TRACE), hallucination detection (LSC), and cost-performance tradeoffs (KAMI). But when it comes to implementing these evaluations, which framework should you use?
Why these 3 frameworks (and not CrewAI, LangGraph, or AutoGen)?
I compared 8 agent frameworks for evaluation capabilities. Most popular frameworks (CrewAI, LangGraph, AutoGen, OpenAI Agents SDK, Google ADK) focus on building agents, not evaluating them. They do not ship dedicated evaluation libraries.
These 3 were selected because they are the only ones with dedicated, open-source evaluation SDKs:
| Framework | Evaluation Library | What It Provides |
|---|---|---|
| Strands Agents | strands-agents-evals | OutputEvaluator, TrajectoryEvaluator, ToolCalled, ActorSimulator, Experiment runner |
| PydanticAI | pydantic-evals | LLMJudge, typed Datasets with YAML, report diffing, HasMatchingSpan |
| DeepEval | deepeval (standalone) | 30+ metrics: GEval, HallucinationMetric, FaithfulnessMetric, ToolCorrectnessMetric |
What about the others?
| Framework | Why Not Included |
|---|---|
| CrewAI | crewai test only supports OpenAI, provides basic 1-10 scoring. No rubrics, no trajectory eval, no hallucination detection. |
| LangGraph | Evaluation lives in LangSmith (paid SaaS), not in the open-source framework. |
| AutoGen | Has AutoGen Bench for benchmarking but no evaluation SDK with comparable metrics. |
| OpenAI Agents SDK | Provides tracing hooks but no evaluation library. Pair it with DeepEval to evaluate. |
| Google ADK | Has adk eval CLI but tightly coupled to the Gemini ecosystem. |
If you use CrewAI, LangGraph, or AutoGen to build your agent, you still need one of these 3 frameworks to evaluate it. DeepEval in particular is framework-agnostic and works with any agent.
What evaluation tasks are we running?
We evaluate the same travel assistant agent scenario across all three frameworks. The agent answers questions from travelers using tools (search flights, check hotel availability, get weather).
- Output Quality - Is the agent’s answer helpful and accurate? (LLM-as-Judge)
- Tool Correctness - Did the agent call the right tools with the right parameters?
- Hallucination Detection - Did the agent fabricate information not in the context?
- Faithfulness - Is the answer grounded in the retrieved information?
Same test cases. Same judge model (Claude on Amazon Bedrock). Same rubrics where possible.
Find all the code here Evaluate AI Agents with Strands
Round 1: Output Quality (LLM-as-Judge)
Quick answer: All three frameworks support LLM-as-Judge with custom rubrics, but Strands requires the fewest lines (7), PydanticAI offers the most configuration options (score + assertion modes), and DeepEval supports the widest range of custom criteria via GEval. Strands and PydanticAI support Bedrock natively; DeepEval requires a custom wrapper.
LLM-as-Judge is the most fundamental evaluation technique: use a large language model to score whether the agent’s output meets quality criteria. All three frameworks support this pattern, but the API differs significantly.
Strands Agents (7 lines)
Strands uses OutputEvaluator with a custom rubric, making it the most concise option for basic LLM-as-Judge:
from strands_evals import Experiment, Case
from strands_evals.evaluators import OutputEvaluator
cases = [
Case(input="Find flights from NYC to London for next Friday",
expected_output="Should include airline, price range, and departure times"),
]
evaluator = OutputEvaluator(
rubric="Rate the response on helpfulness (0-1). A helpful response includes "
"specific flight options with airlines, prices, and times. Penalize "
"vague or generic responses.",
model="us.anthropic.claude-sonnet-4-20250514-v1:0",
)
experiment = Experiment(cases=cases, evaluators=[evaluator])
reports = experiment.run_evaluations(lambda case: agent(case.input))
reports[0].display()PydanticAI (10 lines)
PydanticAI wraps cases in a Dataset and provides separate score and assertion modes, giving you more control over pass/fail criteria:
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import LLMJudge
dataset = Dataset(
cases=[
Case(
name="flight_search",
inputs="Find flights from NYC to London for next Friday",
expected_output="Should include airline, price range, and departure times",
),
],
evaluators=[
LLMJudge(
rubric="Rate the response on helpfulness. A helpful response includes "
"specific flight options with airlines, prices, and times. "
"Penalize vague or generic responses.",
model="anthropic:claude-sonnet-4-6",
include_input=True,
include_expected_output=True,
score={"include_reason": True},
),
],
)
report = dataset.evaluate_sync(lambda inputs: agent(inputs))
report.print(include_input=True)DeepEval (12 lines)
DeepEval uses GEval with explicit evaluation parameters, allowing you to control which fields the judge sees:
from deepeval import evaluate
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
test_case = LLMTestCase(
input="Find flights from NYC to London for next Friday",
actual_output=agent("Find flights from NYC to London for next Friday"),
expected_output="Should include airline, price range, and departure times",
)
metric = GEval(
name="Helpfulness",
criteria="Rate the response on helpfulness. A helpful response includes "
"specific flight options with airlines, prices, and times. "
"Penalize vague or generic responses.",
evaluation_params=[
LLMTestCaseParams.INPUT,
LLMTestCaseParams.ACTUAL_OUTPUT,
LLMTestCaseParams.EXPECTED_OUTPUT,
],
threshold=0.5,
)
result = evaluate(test_cases=[test_case], metrics=[metric])Verdict: Which Framework Wins?
| Aspect | Strands | PydanticAI | DeepEval |
|---|---|---|---|
| Lines of code | 7 | 10 | 12 |
| Bedrock native | Yes | Yes | Custom wrapper needed |
| Score format | 0.0-1.0 | 0.0-1.0 + pass/fail | 0.0-1.0 |
| Reason included | Yes | Yes (configurable) | Yes |
| Batch evaluation | Experiment.run_evaluations() | Dataset.evaluate_sync() | evaluate() |
| Prompting method | Direct rubric → LLM | Direct rubric → LLM | G-Eval (CoT + logprobs) |
Strands is the most concise. PydanticAI offers the most configuration (separate score vs. assertion modes). DeepEval uses GEval, a research-backed technique from the paper “G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment”.
⚠️ Why scores may differ: Even with the same model and rubric text, GEval uses a fundamentally different prompting strategy:
- Chain-of-thought decomposition - Breaks evaluation into explicit steps
- Logprobs weighting - Uses token probabilities to weight scores
- Structured template - Optimized prompt format for human alignment
This is by design. GEval optimizes for correlation with human judgments, not identical scoring to direct rubric prompting. Strands and PydanticAI optimize for transparency and customizability.
Round 2: Tool Correctness Evaluation
Quick answer: Strands provides built-in trajectory extraction and deterministic tool checks (zero cost). DeepEval has a dedicated ToolCorrectnessMetric with LLM-based comparison. PydanticAI’s HasMatchingSpan requires OpenTelemetry instrumentation and is not comparable to the other two for simple tool list validation.
Tool correctness measures whether the agent called the right tools with the right parameters. This is critical for agents that interact with APIs and databases, because a wrong tool call can cause real-world side effects.
⚠️ PydanticAI excluded from direct comparison: PydanticAI’s HasMatchingSpan evaluator requires full OpenTelemetry traces from live agent execution. It cannot evaluate pre-computed tool lists like ["search_flights", "check_availability"], making it fundamentally incomparable to Strands’ ToolCalled and DeepEval’s ToolCorrectnessMetric for basic tool validation.
Strands Agents (with trajectory extraction)
Strands automatically extracts tool usage from agent execution traces, making trajectory evaluation seamless:
from strands_evals import Experiment, Case
from strands_evals.evaluators import TrajectoryEvaluator
from strands_evals.extractors import tools_use_extractor
traj_eval = TrajectoryEvaluator(
rubric="The agent should search for flights first, then check availability. "
"Calling weather tools is optional but acceptable.",
model="us.anthropic.claude-sonnet-4-20250514-v1:0",
)
cases = [
Case(
input="Find flights from NYC to London for next Friday",
expected_trajectory=["search_flights", "check_availability"],
),
]
def task_with_trajectory(case):
agent.messages = []
response = agent(case.input)
traj_eval.update_trajectory_description(
tools_use_extractor.extract_tools_description(agent)
)
trajectory = tools_use_extractor.extract_agent_tools_used_from_messages(
agent.messages
)
return {"output": str(response), "trajectory": trajectory}
experiment = Experiment(cases=cases, evaluators=[traj_eval])
reports = experiment.run_evaluations(task_with_trajectory)Bonus: Deterministic tool check (no LLM needed, zero cost)
For simple “was this tool called?” checks, Strands provides instant verification with no API calls:
from strands_evals.evaluators import ToolCalled
# Check if a specific tool was called (instant, no API call)
experiment = Experiment(
cases=cases,
evaluators=[ToolCalled(tool_name="search_flights")],
)PydanticAI (with span-based tool detection)
PydanticAI uses OpenTelemetry spans to detect tool usage, requiring custom evaluator code for trajectory validation:
from dataclasses import dataclass
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import Evaluator, EvaluatorContext, HasMatchingSpan
dataset = Dataset(
cases=[
Case(
name="flight_search",
inputs="Find flights from NYC to London for next Friday",
metadata={"expected_tools": ["search_flights", "check_availability"]},
),
],
evaluators=[
HasMatchingSpan(
query={"name_contains": "search_flights"},
evaluation_name="called_search_flights",
),
],
)
# Custom evaluator for full trajectory check
@dataclass
class ToolSequenceCheck(Evaluator):
def evaluate(self, ctx: EvaluatorContext) -> dict[str, bool]:
tool_spans = ctx.span_tree.find(lambda n: "tool" in n.name.lower())
tool_names = [s.name for s in tool_spans]
expected = ctx.metadata.get("expected_tools", [])
return {
"all_tools_called": all(t in tool_names for t in expected),
"correct_order": self._check_order(tool_names, expected),
}
def _check_order(self, actual, expected):
positions = []
for tool in expected:
if tool in actual:
positions.append(actual.index(tool))
return positions == sorted(positions)DeepEval (with ToolCall objects)
DeepEval uses structured ToolCall objects with explicit parameter validation and ordering checks:
from deepeval import evaluate
from deepeval.metrics import ToolCorrectnessMetric
from deepeval.test_case import LLMTestCase, ToolCall
test_case = LLMTestCase(
input="Find flights from NYC to London for next Friday",
actual_output="I found 3 flights...",
tools_called=[
ToolCall(name="search_flights", input_parameters={"origin": "NYC", "dest": "LHR"}),
ToolCall(name="check_availability", input_parameters={"flight_id": "BA117"}),
],
expected_tools=[
ToolCall(name="search_flights", input_parameters={"origin": "NYC", "dest": "LHR"}),
ToolCall(name="check_availability"),
],
)
metric = ToolCorrectnessMetric(
threshold=0.5,
should_consider_ordering=True,
should_exact_match=False,
)
result = evaluate(test_cases=[test_case], metrics=[metric])Verdict: Which Framework Wins?
| Aspect | Strands | PydanticAI | DeepEval |
|---|---|---|---|
| Trajectory extraction | Built-in extractor | Via OpenTelemetry spans | Manual ToolCall objects |
| LLM-based trajectory eval | TrajectoryEvaluator | Not comparable (OTEL-only) | ToolCorrectnessMetric |
| Deterministic check | ToolCalled (zero-cost) | HasMatchingSpan (OTEL-only) | N/A |
| Ordering validation | in_order_match_scorer | Custom code | should_consider_ordering |
| Parameter validation | Via rubric | Via span attributes | should_exact_match |
| Works with pre-computed tool lists | Yes | No (requires live traces) | Yes |
Strands wins for simplicity with built-in trajectory extraction from agent messages. DeepEval has the most structured ToolCall API with dedicated LLM-based comparison. PydanticAI is the most flexible via span trees but requires OpenTelemetry instrumentation, making it suitable only for live agent evaluation, not pre-computed analysis.
Round 3: Hallucination Detection
Quick answer: DeepEval provides a purpose-built HallucinationMetric that decomposes claims and checks each against context. Strands and PydanticAI use general-purpose LLM-as-judge with custom rubrics, which is flexible but less specialized. DeepEval wins for hallucination detection with its dedicated metric and per-context contradiction counting.
Hallucination detection measures whether the agent fabricates information not present in the source context. This is one of the most critical evaluation dimensions, with recent research (LSC, Jan 2026) showing that zero-shot detection methods can identify fabricated content without any training data.
Strands Agents
Strands uses OutputEvaluator with a hallucination-focused rubric:
from strands_evals import Experiment, Case
from strands_evals.evaluators import OutputEvaluator
cases = [
Case(
input="What is the baggage policy for Delta flights to London?",
expected_output="Based on the context: 2 checked bags, 23kg each, free for international",
),
]
hallucination_eval = OutputEvaluator(
rubric="Score 1.0 if the response ONLY contains information present in the "
"expected output (ground truth). Score 0.0 if the response includes "
"any fabricated details such as specific prices, dates, or policies "
"not mentioned in the ground truth. Partially correct responses "
"should score between 0.3-0.7.",
model="us.anthropic.claude-sonnet-4-20250514-v1:0",
)
experiment = Experiment(cases=cases, evaluators=[hallucination_eval])
reports = experiment.run_evaluations(lambda case: agent(case.input))PydanticAI
PydanticAI uses LLMJudge with separate score and assertion modes for hallucination detection:
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import LLMJudge
dataset = Dataset(
cases=[
Case(
name="baggage_policy",
inputs="What is the baggage policy for Delta flights to London?",
expected_output="Based on the context: 2 checked bags, 23kg each, free for international",
),
],
evaluators=[
LLMJudge(
rubric="Does the response ONLY contain information present in the "
"expected output? Score 0.0 for fabricated details, 1.0 for "
"fully grounded responses.",
model="anthropic:claude-sonnet-4-6",
include_expected_output=True,
score={"include_reason": True, "evaluation_name": "hallucination"},
assertion={"include_reason": True, "evaluation_name": "grounded"},
),
],
)
report = dataset.evaluate_sync(lambda inputs: agent(inputs))DeepEval (dedicated HallucinationMetric)
DeepEval provides a specialized HallucinationMetric that decomposes responses into claims and verifies each against the source context:
from deepeval import evaluate
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What is the baggage policy for Delta flights to London?",
actual_output=agent("What is the baggage policy for Delta flights to London?"),
context=[
"Delta international flights include 2 checked bags at 23kg each, free of charge.",
"Carry-on must fit in overhead bin. One personal item allowed.",
],
)
metric = HallucinationMetric(threshold=0.5)
result = evaluate(test_cases=[test_case], metrics=[metric])Verdict: Which Framework Wins?
| Aspect | Strands | PydanticAI | DeepEval |
|---|---|---|---|
| Dedicated metric | No (via OutputEvaluator rubric) | No (via LLMJudge rubric) | Yes (HallucinationMetric) |
| Context as input | Via expected_output | Via expected_output | Dedicated context field |
| Scoring method | LLM judge with rubric | LLM judge with rubric | Claim-by-claim verification |
| Granularity | Single score | Score + assertion | Per-context contradiction count |
DeepEval wins here with a purpose-built HallucinationMetric that decomposes claims and checks each against context. Strands and PydanticAI use general-purpose LLM-as-judge with custom rubrics. This approach is flexible but less specialized for hallucination detection.
Round 4: Batch Evaluation
Quick answer: PydanticAI has the best reporting with baseline diffing (compare v1 vs v2). DeepEval has the most metrics out-of-the-box (30+). Strands has the cleanest API for mixing LLM and deterministic evaluators in a single experiment.
Real-world evaluation runs multiple metrics on multiple test cases at the same time. This section compares how each framework handles parallel execution, mixed metric types, and reporting.
Strands Agents
Strands combines multiple evaluators in a single Experiment, automatically running all combinations:
from strands_evals import Experiment, Case
from strands_evals.evaluators import (
OutputEvaluator, TrajectoryEvaluator, ToolCalled,
)
cases = [
Case(input="Find flights NYC to London",
expected_output="Flight options with prices",
expected_trajectory=["search_flights"]),
Case(input="What's the weather in Paris tomorrow?",
expected_output="Temperature and conditions",
expected_trajectory=["get_weather"]),
Case(input="Book hotel in Tokyo for 3 nights",
expected_output="Booking confirmation with dates and price",
expected_trajectory=["search_hotels", "book_hotel"]),
]
experiment = Experiment(
cases=cases,
evaluators=[
OutputEvaluator(rubric="Is the response helpful and specific?"),
TrajectoryEvaluator(rubric="Did the agent use the right tools?"),
ToolCalled(tool_name="search_flights"),
],
)
reports = experiment.run_evaluations(task_function)
for report in reports:
report.display()PydanticAI
PydanticAI uses Dataset.evaluate_sync() with a max_concurrency parameter for parallel execution:
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import LLMJudge, EqualsExpected, HasMatchingSpan
dataset = Dataset(
cases=[
Case(name="flights", inputs="Find flights NYC to London",
expected_output="Flight options with prices"),
Case(name="weather", inputs="What's the weather in Paris tomorrow?",
expected_output="Temperature and conditions"),
Case(name="hotel", inputs="Book hotel in Tokyo for 3 nights",
expected_output="Booking confirmation with dates and price"),
],
evaluators=[
LLMJudge(rubric="Is the response helpful and specific?",
score={"include_reason": True}),
],
)
report = dataset.evaluate_sync(task_function, max_concurrency=3)
report.print(include_input=True, include_averages=True)DeepEval
DeepEval uses AsyncConfig to control parallel execution and supports the widest range of built-in metrics:
from deepeval import evaluate
from deepeval.metrics import (
GEval, AnswerRelevancyMetric, HallucinationMetric, ToolCorrectnessMetric,
)
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.evaluate.configs import AsyncConfig
test_cases = [build_test_case(q) for q in questions]
metrics = [
GEval(name="Helpfulness",
criteria="Is the response helpful and specific?",
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT]),
AnswerRelevancyMetric(threshold=0.7),
HallucinationMetric(threshold=0.5),
]
result = evaluate(
test_cases=test_cases,
metrics=metrics,
async_config=AsyncConfig(max_concurrent=5),
)Verdict: Which Framework Wins?
| Aspect | Strands | PydanticAI | DeepEval |
|---|---|---|---|
| Parallel execution | run_evaluations_async() | max_concurrency param | AsyncConfig(max_concurrent=N) |
| Mixed metric types | LLM + deterministic | LLM + deterministic + span | LLM only (30+ metrics) |
| Report format | Rich table via .display() | Rich table via .print() | Console + Confident AI dashboard |
| Report diffing | No | Yes (baseline= param) | Via Confident AI |
| Export | JSON file | YAML/JSON file | JSON/CSV + cloud |
PydanticAI has the best reporting with baseline diffing (compare v1 vs v2). DeepEval has the most metrics out-of-the-box. Strands has the cleanest API for mixing LLM and deterministic evaluators.
What is the complete feature comparison?
This table summarizes every evaluation capability across all three frameworks. Use it as a reference when choosing a framework for your specific evaluation needs.
| Feature | Strands + evals | PydanticAI + evals | DeepEval |
|---|---|---|---|
| LLM-as-Judge | OutputEvaluator | LLMJudge | GEval |
| Trajectory evaluation | TrajectoryEvaluator + extractors | SpanTree + custom | ToolCorrectnessMetric |
| Hallucination detection | Via rubric | Via rubric | HallucinationMetric |
| Faithfulness | FaithfulnessEvaluator (trace) | Via rubric | FaithfulnessMetric |
| Deterministic checks | Equals, Contains, ToolCalled | Equals, Contains, IsInstance | N/A |
| Multi-agent evaluation | InteractionsEvaluator | Custom evaluator | N/A |
| Multi-turn simulation | ActorSimulator | N/A | ConversationalTestCase |
| Test case generation | ExperimentGenerator | N/A | deepeval generate |
| Bedrock native | Yes | Yes | Custom wrapper |
| OpenTelemetry | Built-in | Via Logfire | N/A |
| Dataset serialization | JSON | YAML/JSON | JSON/CSV |
| Report comparison | No | Baseline diffing | Confident AI |
| pytest integration | Via Experiment | dataset.evaluate_sync() | assert_test() / deepeval test |
| Total built-in metrics | 12 evaluators | 6 evaluators + custom | 30+ metrics |
Try it yourself
The companion notebook runs all comparisons with live code. You can reproduce every result from this post.
A companion Jupyter notebook with executable code examples is available in the GitHub repository. The notebook includes side-by-side comparisons of all three frameworks on the same evaluation tasks.
Setup
cd blog-framework-comparison
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txtFrequently asked questions
Which AI agent evaluation framework is easiest to learn? Strands Agents requires the fewest lines of code (7 lines for LLM-as-Judge). PydanticAI is close at 10 lines. DeepEval requires the most setup, especially for non-OpenAI models where you need a custom wrapper class.
Do Strands, PydanticAI, and DeepEval support Amazon Bedrock?
Strands and PydanticAI support Bedrock natively (one-line configuration). DeepEval requires a custom DeepEvalBaseLLM wrapper that maps Bedrock’s API to DeepEval’s interface. The wrapper adds approximately 25 lines of code.
Do I need OpenTelemetry to evaluate AI agents?
Only for trace-based evaluators in Strands (such as FaithfulnessEvaluator and ToolSelectionAccuracyEvaluator). Output-based evaluators in all three frameworks work without OpenTelemetry. PydanticAI uses OpenTelemetry via Logfire for span-based evaluation.
What is the cost of running AI agent evaluations?
Every LLM-based evaluator makes API calls to the judge model, which incurs token costs. Strands provides deterministic evaluators (such as ToolCalled, Equals, Contains) that run instantly at zero cost. DeepEval and PydanticAI also have deterministic options (Equals, Contains, IsInstance).
Can I use multiple evaluation frameworks together?
Yes. You can use DeepEval’s specialized metrics (such as HallucinationMetric) alongside Strands Agents for the agent runtime and trajectory capture. The frameworks evaluate outputs, not agents directly, so the agent framework and evaluation framework are independent choices.
Conclusion
There is no single “best” evaluation framework. The right choice depends on your stack, priorities, and what you’re comparing.
Key takeaway: Different methodologies produce different scores by design.
- Strands and PydanticAI send rubrics directly to the LLM (transparent, customizable)
- DeepEval uses research-backed techniques like G-Eval (optimized for human alignment)
- PydanticAI requires OpenTelemetry for tool evaluation (live traces only)
- Strands and DeepEval work with pre-computed data (simpler testing)
When to use each:
Strands Agents is the most cohesive option if you build on AWS. Agent creation, tool calling, trajectory capture, and evaluation live in the same ecosystem. The hooks system and built-in metrics mean evaluation is instrumented into the agent runtime, not bolted on after the fact. Best for AWS-first teams who want tight integration.
PydanticAI is the most elegant option if you value type safety and structured evaluation pipelines. YAML datasets, report diffing, and the Evaluator protocol make it ideal for teams that want evaluation-as-code with strong guarantees. Best for teams prioritizing type safety and reproducible pipelines.
DeepEval is the most comprehensive option if you want specialized metrics without building them yourself. Over 30 metrics, including purpose-built hallucination detection and faithfulness checking, let you evaluate immediately without writing custom rubrics. Best for framework-agnostic evaluation with research-validated techniques.
The evaluation concepts (LLM-as-judge, trajectory scoring, hallucination detection) are framework-independent. The research papers and techniques behind them work regardless of which framework you choose. For the full list of 45+ papers that informed this comparison, see the RESEARCH.md file.
Amazon Bedrock AgentCore: A Fourth Option
Amazon Bedrock AgentCore provides built-in evaluators and managed deployment for agents. If you’re committed to AWS and want a fully managed solution, AgentCore is worth considering alongside the open-source frameworks.
Built-In Evaluators
AgentCore includes 13 pre-built evaluators accessible via the AgentCore CLI and AWS SDK. These evaluators cover common evaluation dimensions without requiring custom code:
| Evaluator | What It Measures | When to Use |
|---|---|---|
Builtin.Helpfulness | Output quality and relevance | Same use case as Strands OutputEvaluator |
Builtin.GoalSuccessRate | Task completion accuracy | Binary success metric (compare to trajectory scoring) |
Builtin.ToolSelection | Tool choice correctness | Same as Strands ToolCalled or DeepEval ToolCorrectnessMetric |
Builtin.Faithfulness | Grounding in retrieved context | Same as DeepEval FaithfulnessMetric |
Builtin.Harmfulness | Safety and policy compliance | Detects unsafe outputs |
How evaluations work: You invoke the agentcore run eval CLI command with your agent ID, the desired evaluator name (such as Builtin.Helpfulness), and a test cases file. AgentCore runs the agent on each test case and returns a JSON report with scores and reasoning for each query. See the AgentCore Evaluation Guide for examples.
Trace Capture for Observability
AgentCore captures full execution traces when you enable the enableTrace parameter in the invoke_agent API call. Traces include:
- Rationale: The agent’s reasoning before each tool call
- Tool invocations: Which tools were called with what parameters
- Observations: Results returned from each tool
- Orchestration steps: The full decision-making sequence
All traces are automatically logged to Amazon CloudWatch for analysis and monitoring. You can query traces using CloudWatch Logs Insights or export them to S3 for batch analysis. See the Bedrock Agent Tracing Documentation for trace schema details.
When to use AgentCore:
- You’re already on AWS and want a managed service
- You need CloudWatch-native observability and compliance logging
- Your team prefers infrastructure-as-code (CDK/CloudFormation) over custom evaluation scripts
- You don’t need to evaluate agents on other cloud providers
When to use open-source frameworks:
- Multi-cloud deployment (Strands works with Bedrock, OpenAI, Anthropic, Ollama)
- Need fine-grained control over evaluation logic
- Want to iterate quickly on custom metrics without deploying Lambda functions
- Research or prototyping where flexibility matters more than managed infrastructure
AgentCore Resources
Gracias!